
In administrative software, one of the most common forms is a data grid. It appears in many parts of the application for reports, alerts, or just as a representation of the system objects. Data grids are a great candidate for a wrapper around the tools you use to generate them. Dynamic queries aim to give you a centralized way to create data grids and customize their appearance and data just by configuration. This article aims to show how to centralize data grids in a software application. We are also describing common problems you can face while developing data grid-oriented software, solutions with a dynamic query approach, and technical implementation details to adopt the pattern.
What are data grids?
A distributed computing architecture called a data grid makes it possible to analyze and store vast amounts of data across numerous networked servers or nodes. It serves as a virtualized data repository that enables scalable and fault-tolerant storing and retrieval of large datasets by enterprises.
Key features
Just some of the functionalities of data grids are:
- Distributed storage: Data grids enable horizontal scaling by distributing data among several nodes or servers. Data availability, scalability, and fault tolerance are improved by this distributed storage strategy.
- Parallel processing: Data grids use parallel processing techniques to analyze data across distant datasets and carry out calculations. High-performance data processing is made possible by this since numerous nodes can carry out tasks simultaneously.
- Data partitioning: Large datasets are divided into smaller portions or partitions, and these values are dispersed over several nodes in data grids. Effective load balancing, parallel processing, and data distribution are made possible by this partitioning technique.
Main benefits
- Scalability: Large and expanding datasets’ storage requirements can be met by data grids, which offer scalable processing and storage options. Data grids can manage increased data volumes by scaling horizontally without compromising performance or reliability by distributing data over several nodes.
- Improved performance: High-performance data processing and analytics are made possible by data grids’ dynamic properties for in-memory computing, research effort, and parallel processing. Large dataset analysis and sophisticated computations can be carried out by organizations with low processing overhead and delay.
- Reduced costs: Organizations can cut expenses by using data grids instead of more conventional methods for processing and storing data. Utilizing open-source software and commodity hardware, data grids provide affordable substitutes for proprietary analytics and database systems.
All of these benefits find various use cases across industries.
Common use cases for data grids in various industries
- Finance: data grids can be utilized for real-time fraud detection, risk management, high-frequency trading, or customer analytics
- Healthcare: healthcare professionals can rely on data grids for medical imaging analysis, patient record management or genomic analysis.
- Manufacturing: such technology is also invaluable for predictive maintenance, quality control or even production optimization.
However, just as with everything, developing data grid-oriented applications presents some challenges.
Some setbacks
Repeating code
There are many ways that show how to generate the grids with external libraries. However, no matter what you value, you end up with big pieces of code repeating all over your application. The problem is that most of the libraries you use support more functionalities than the typical form actually needs.
Limitations of traditional querying methods in data grids
Traditional querying techniques in data grids might be rigid and have trouble handling complicated queries and a variety of data formats. Complicating matters are security considerations about data protection and access management in distributed situations. Furthermore, its inflexible framework frequently fails to address the increasing amount of non-relational data, which impedes insightful analysis.
Often changing requirements related to data appearance
Parts of the appearance of the data grid, such as paging, records number shown on a page, ability to sort or filter a column, initial sort or filter, can be frequently changed in order to respond to every user’s requirements and personal experience.
Often changing requirements related to data nature
A data set is potentially prone to change due to changing business requirements. For example, over time specific data may require a combination with different data which will change its origin query.
Changing data requirements
In dynamic data environments, static queries become fragile, unable to adapt to changing analytical requirements or new data structures. This rigidity limits important insights from new or altered data and adds to maintenance burdens.
Performance bottlenecks and scalability concerns when querying large datasets
Scalability is hampered by performance constraints revealed by querying huge datasets, such as data transportation across the grid and insufficient parallel processing. These restrictions result in slower response times and possible strain on the infrastructure as data volume increases, which makes efficient analysis more difficult.
Authorization problem
This problem is related to safety and the idea of not exposing data unintended for the user. To tackle all of the problems, we decided to expose a centralized part of the code for creating data grids. In the database, we have the following structure:
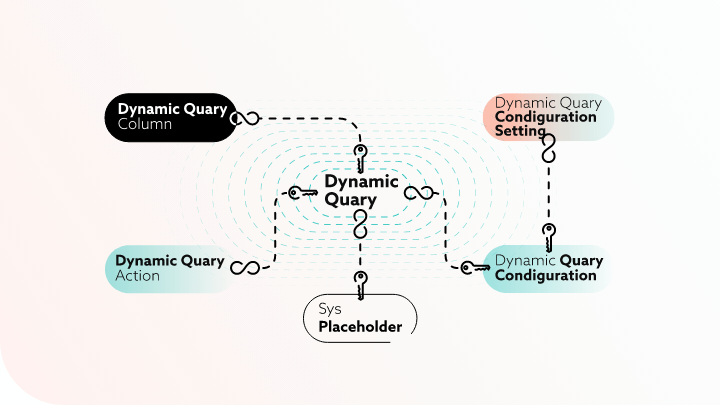
In the SysPlaceholder table we store SQL queries which have the role of dynamic database views.
In the DynamicQuery table we make a relation between the SQL and the actual data grid object. Using different settings, multiple grids can share a common SQL query for their origin data.
Dynamic query configuration and dynamic query configuration setting
Configuration uses two tables – DynamicQueryConfiguration and DynamicQueryConfigurationSetting. There is a set of configuration rules assigned to the dynamic query for easier maintaining of a large number of settings. For example, you can have a configuration “Standard view” – that contains the settings – paging, filtering, etc. and another one – “Simple view” – which has only paging.
Columns of the data grid are described in the DynamicQueryColumn table which contains different metadata for the columns, like title, order, is the column has sorting or filtering, it’s datatype etc. It is important to note that the workname of the column should match a selected field from the SQL. For example, if we have the column City in the SysPlaceholder used by the DQ, we need to have Select [sth] as City from [table].
Often, in the data grid we don’t have only data. DynamicQueriesAction is a table that stores different actions which the grid can have. Every action has handler which can be standard button, special button, select of the row, action in the toolbar of the grid, etc. It also has an ActionName which refers to a name of a function in the front-end.
The backend service in our case is a web API OData controller. An obstacle we faced here was to create a view model with dynamic properties. We used Odata Open types [1]. We also used IQuerable [2] functionality in .NET. The automatic generation of SQL statements gave us the ability to manage the authorization. We created a helper that gets filtered subset from every table. It, then, replaces the sets referred from the SysPlaceholder SQL with these subsets by string replacement in the SQL string.
In the front end, we have created a wrapper object that takes care of the visualization of the grid. It communicates with the backend service and it is with different unique dynamic queries id-s from different parts of the client’s code.
Best practices for dynamic queries

Dynamic queries can be utilized in several beneficial ways. The first is to enhance security by verifying and cleaning up every input from users to stop injection attacks. To achieve these benefits one must be wary of special characters and configure stringent formatting guidelines. Another security measure is to use parameterized queries to help keep user input isolated from the query string, protecting your system from dangerous code.
Lastly, another practice that must always be utilized is to be pre-emptively vigilant. People need to regularly analyze query performance to find and fix any slow queries that require improvement. But most importantly, deal with performance concerns early on or even before they arise to maintain the responsiveness and effectiveness of your data grid.
Conclusion
Using the centralized way of creating data grids – dynamic queries – we were able to simplify and speed up the software development. We write less code and we are more flexible to change the appearance of the data grids just from configuration, without the need for redeployment procedures. We have cleared our way to create a Dynamic Query administration and even enabled the users of our product to manage all configurations by themselves. In addition, one of the main benefits is the security. Thus, all of our queries are safe and the whole client code has access to save a subset of the data.
REFERENCES
https://blogs.msdn.microsoft.com/odatateam/2014/07/20/tutorial-sample-open-complex-type-step-by-step-with-web-api-2-2-for-odata-v4-0/ http://stackoverflow.com/questions/34354230/where-to-find-translated-linq-to-entity-query-to-sql

BGO Software is a renowned IT company specializing in healthcare technology solutions. With over 15 years of industry experience, we offer comprehensive technology consulting, software development, and IT infrastructure services. Our focus on healthcare technology enables businesses to mitigate technological risks and accelerate growth, ultimately delivering enhanced value to patients.
link to the author’s linkedin profile